MiBeeSteward:为什么我选择用 Go 重新造一个设备管理轮子
做工作室运维,最头疼的从来不是某个具体问题,而是设备多起来之后的「不知道」。
不知道哪个设备还活着,不知道它上面跑了什么服务,不知道网络里什么时候多了台新机器,不知道某个端口是不是还开着——这种「不知道」积累到最后就是故障。
之前我为了解决这些问题,方案是拼凑的:Zabbix 做监控,Nmap 扫网络,Excel 记资产,Prometheus 看指标。每个工具单独看都不错,但合在一起就是灾难——数据孤岛、重复配置、版本漂移、部署复杂。
于是我用 Go 重新做了一个:MiBeeSteward。一个二进制解决设备管理、网络发现、协议探测、指标监控的全链路工具。
项目已经开源:https://github.com/Mi-Bee-Studio/MiBeeSteward
MiBeeSteward 是什么
MiBeeSteward 是一个设备管理与监控系统,核心定位是「用最少的运维成本,搞清楚网络里发生了什么」。
它不是一个 NVR,也不是一个告警平台——它做的事情是把网络设备的发现 → 分类 → 监控 → 管理串成一条线,塞进一个二进制文件里。
整体架构
flowchart TD
SPA["SvelteKit 5 SPA"] --> ROUTER["Chi + Middleware"]
ROUTER --> SERVICE["Service Layer"]
SERVICE --> REPO["Repository & sqlc"]
REPO --> SQLITE[("SQLite WAL")]
SERVICE --> BG["Heartbeat 10s"]
classDef front fill:#E3F2FD,stroke:#1565C0,color:#1565C0
classDef svc fill:#FFF3E0,stroke:#E65100,color:#BF360C
classDef data fill:#E8F5E9,stroke:#2E7D32,color:#1B5E20
class SPA,ROUTER front
class SERVICE,BG svc
class REPO,SQLITE data标准的 DDD 分层。前端 SvelteKit 5 通过 go:embed 嵌入二进制,部署只需要一个文件。
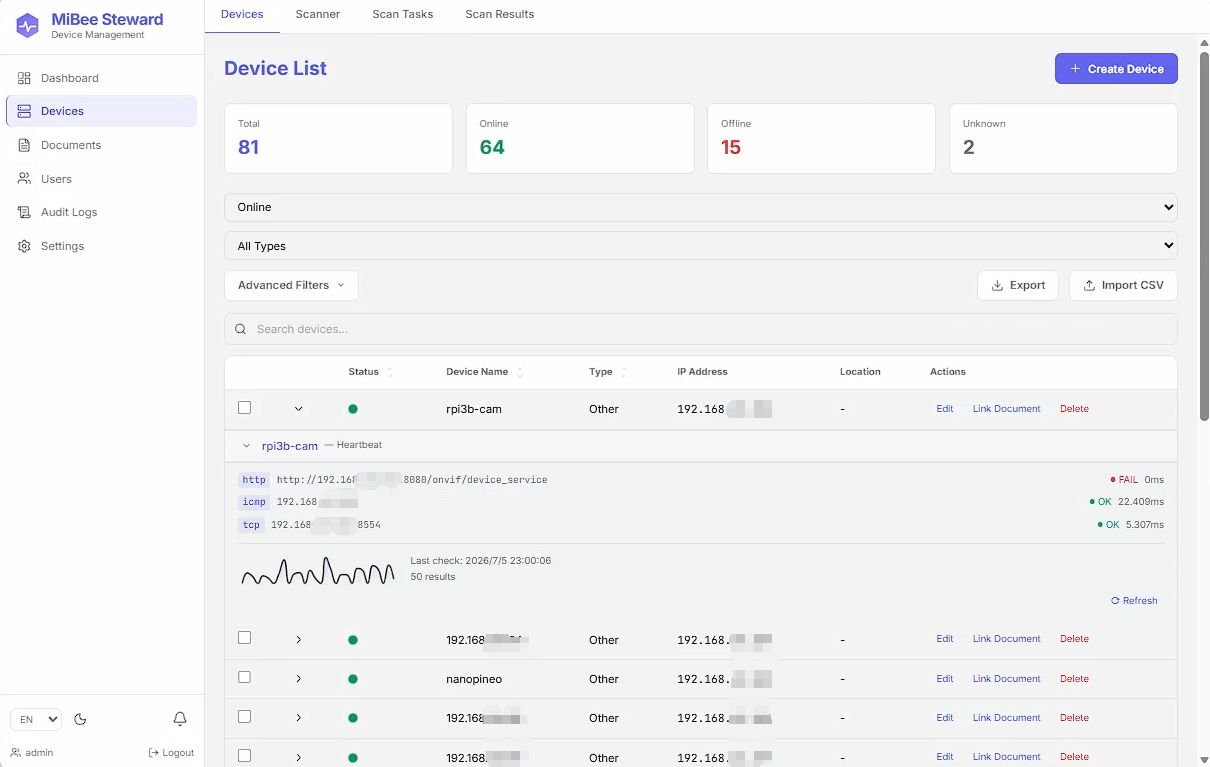
设备列表页——顶部展示统计卡片(总计 81 / 在线 64 / 离线 15 / 未知 2),下方是设备表格,包含心跳状态、IP、类型和操作按钮。
技术栈
| 层 | 选型 | 理由 |
|---|---|---|
| 后端 | Go 1.26+ / Chi v5 | 性能好、交叉编译方便、单一二进制 |
| 数据库 | SQLite (modernc.org/sqlite) | 纯 Go 实现,CGO_ENABLED=0,单文件 |
| 查询生成 | sqlc | 类型安全,开发效率高 |
| 配置管理 | koanf/v2 | 支持 YAML + 环境变量覆盖 |
| 认证 | JWT (go-chi/jwtauth) | Cookie 优先 + Bearer 回退 |
| 前端 | SvelteKit 5 + Tailwind 4 + ECharts | 编译产物小,响应式,内嵌无负担 |
| 国际化 | @inlang/paraglide-js | 中英双语,编译期消息内联 |
| 探测 | gosnmp / pro-bing / net/http | 原生支持 SNMP/ICMP/TCP/HTTP |
| eBPF | cilium/ebpf | 可选编译标签,默认无依赖 |
核心功能深度解析
1. 多协议探测(Probe Subsystem)
设备监控最基础的能力就是「定期问它一声还活着没」。但不同设备、不同场景需要的探测方式完全不同。
MiBeeSteward 采用接口化设计 + 装饰器模式的 Prober 架构:
flowchart TD
PROBER["Prober 接口"] --> IMPL["ICMP · TCP<br/>HTTP · SNMP"]
PROBER --> RETRY["RetryProber"]
RETRY -->|"指数退避"| PROBE["执行探测"]
PROBE --> OK["✅ 在线"]
PROBE --> FAIL["❌ 离线 (3 次)"]
classDef iface fill:#E3F2FD,stroke:#1565C0,color:#1565C0
classDef impl fill:#FFF3E0,stroke:#E65100,color:#BF360C
classDef out fill:#E8F5E9,stroke:#2E7D32,color:#1B5E20
class PROBER iface
class IMPL,RETRY,PROBE impl
class OK,FAIL out图中 4 种探测方式统一实现 Prober 接口。装饰器模式提供指数退避重试(1s→2s→4s),连续 3 次失败才标记离线,恢复后自动重新上线。 心跳监控采用三振出局(Three-strike)策略:连续 3 次探测失败才标记离线,避免网络抖动导致误报。恢复时自动重新标记在线,不需要人工介入。
2. 插件式网络扫描器 v2(核心亮点)
这是 MiBeeSteward 最独特的能力。传统的网络发现工具有两类:
- 扫描器类(Nmap、masscan):只做端口扫描,不关心业务含义
- 监控类(Zabbix、Prometheus):假设你已经知道要监控什么
MiBeeSteward 的 Scanner v2 试图填平这个鸿沟——扫描之后自动识别设备类型和服务,5 层插件架构:
flowchart TD
P1["① Probe"] --> P2["② Classifier"]
P2 --> P3["③ ServiceHandler"]
P3 --> P4["④ Persistence"]
P4 --> P5["⑤ Orchestrator"]
classDef step fill:#FFF3E0,stroke:#E65100,color:#BF360C
class P1,P2,P3,P4,P5 step5 层架构将发现流程解耦为独立插件层:Probe 负责探测,Classifier 做协议分类,ServiceHandler 做深度采集,Persistence 持久化,Orchestrator 编排整个流程。
分类器支持级联深度采集,自动发现节点上的更多服务:
flowchart TD
CLS["分类器"] --> SSH["SSH"]
CLS --> HTTP["HTTP"]
CLS --> CAM["RTSP+ONVIF+SNMP"]
HTTP --> COLL["检测 /metrics<br/>→ node_exporter<br/>→ CPU/内存"]
classDef clsf fill:#E3F2FD,stroke:#1565C0,color:#1565C0
classDef coll fill:#E8F5E9,stroke:#2E7D32,color:#1B5E20
class CLS,SSH,HTTP,CAM clsf
class COLL coll开箱即识别的服务:
| 分类器 | 探测方式 | 识别目标 | 附带信息 |
|---|---|---|---|
| SSH | TCP 端口 + 特征字节 | SSH 服务 | 版本号 |
| HTTP | HTTP GET 响应 | Web 服务 / API | Server 头、页面标题 |
| RTSP | TCP 端口 + 协议握手 | 摄像头/视频流 | 支持的方法集 |
| ONVIF | WS-Discovery 组播 | 兼容摄像头 | 设备型号、厂商 |
| SNMP | SNMP get | 网络设备 | sysDescr、OID、企业号 |
| Prometheus | HTTP /metrics 端点 | Prometheus 目标 | 指标列表 |
| node_exporter | 级联检测 | 主机信息 | CPU/内存/磁盘/内核 |
扩展新协议只需三步:
- 实现
ServiceClassifier接口(把 Evidence 分类成 ServiceIdentity) - 实现
ServiceHandler接口(定义如何深度采集该服务) - 在
classify.DefaultClassifiers()和handler.DefaultHandlers()中注册
不需要修改 Orchestrator 和 持久化层。
3. eBPF 被动观测器
这是实验性功能,通过构建标签 make build-with-ebpf 启用(需要 clang/llvm/bpftool + 内核 BTF ≥ 5.8)。
TC ingress 程序挂载在网卡上,嗅探两件事:
- ONVIF WS-Discovery 组播(239.255.255.250:3702)——发现网络中的摄像头
- TCP 特征字节——识别 SSH、RTSP、HTTP 等协议握手
作为主动探测的旁证,置信度设为 0.6,与主动扫描结果融合。默认构建使用 no-op stub,二进制不引入任何 eBPF 依赖。
4. 设备系统管理
每台设备可以挂载多个「系统」——本质上是在设备粒度之上再细分一层:
| |
每个系统可以独立配置 metrics 端点,自动通过 /sd 暴露给 Prometheus 做服务发现。前端以分类徽章卡片网格展示,支持 web_app、database、middleware、custom 四种分类。
5. Prometheus 原生集成
MiBeeSteward 不是「上报数据到 Prometheus」,而是本身就是 Prometheus 生态的一部分:
/metrics— 标准的 Prometheus 指标端点(Gauge / Counter / Histogram)/sd— Prometheus HTTP SD(服务发现),自动输出所有设备和设备系统- Dashboard 代理 —
/api/v1/dashboard/query只读代理,可以从已有的 Prometheus 查数据
这意味着你可以直接把 MiBeeSteward 扔进现有的 Prometheus + Grafana 体系,不需要额外的 exporter 或 relabel 配置。
同类产品全面横评
MiBeeSteward 做的是一个「跨领域的组合」——它横跨了设备资产管理、网络监控、网络发现、Prometheus 生态四个领域。每个领域都有成熟的方案,但 MiBeeSteward 的选择是各取一部分揉在一个二进制里。
下面分领域详细对比。
领域一:设备资产管理
| 特性 | MiBeeSteward | NetBox | Device42 | 自建 Excel/GLPI |
|---|---|---|---|---|
| 部署方式 | 单二进制 | Python + PostgreSQL + Redis | 商业设备 | 取决于方案 |
| 资源占用 | < 100MB 内存 | ~2GB+ 内存 | 商业 | 不定 |
| 自动发现 | ✅ Scanner v2 插件式 | ❌ 手工录入为主 | ✅ 自动发现 | ❌ |
| 协议探测 | ✅ SNMP/ICMP/TCP/HTTP | ❌ | ✅ | ❌ |
| API | ✅ RESTful | ✅ RESTful | ✅ RESTful | ❌ |
| 前端 | ✅ SvelteKit SPA(内嵌) | ✅ Django UI | ✅ Web UI | ❌ |
| 扩展性 | 插件式 Classifier + Handler | 插件/Webhook | 商业支持 | N/A |
NetBox 是目前最流行的开源 DCIM(数据中心基础设施管理),功能非常完善,但它本质上是资产管理数据库,不关心设备是否在线、响应是否正常。MiBeeSteward 的方向相反——以「还活着吗」为核心,资产管理是副产品。
领域二:网络监控
| 特性 | MiBeeSteward | Zabbix | Nagios | Checkmk | LibreNMS |
|---|---|---|---|---|---|
| 部署方式 | 单二进制 | 复杂(Server/Proxy/DB/Web) | 复杂 | Server + Agent | PHP + MySQL |
| CGO 依赖 | ❌ 不需要 | ✅ C 扩展多 | ✅ C 依赖 | ✅ C 依赖 | ✅ |
| 学习成本 | 极低 | 高 | 高 | 中 | 中 |
| 单机部署 | ✅ 开箱即用 | ❌ 至少 3 个组件 | ❌ 复杂 | ⚠️ 需要设置 | ⚠️ 需要 LNMP |
| 自动发现网络 | ✅ Scanner v2 | ✅ Network Discovery | ❌ | ✅ | ✅ |
| Prometheus 集成 | ✅ 原生 | ❌ 需额外配置 | ❌ | ✅ | ⚠️ 有限 |
| 资源占用 | < 100MB | 视规模(通常 1GB+) | 视规模 | 视规模 | 视规模 |
| SQLite | ✅ | ❌ 需要 DB | ❌ 需要 DB | ❌ 需要 DB | ❌ 需要 MySQL |
| 告警系统 | ❌(可通过 Prometheus + Alertmanager) | ✅ 完善 | ✅ 完善 | ✅ 完善 | ✅ |
| 历史数据 | ❌(Prometheus 短期) | ✅ 内置历史 | ✅ 内置历史 | ✅ 内置历史 | ✅ RRD |
关键差异:Zabbix/Nagios/Checkmk 是「重型监控平台」,一个完整部署需要数据库、Web 服务器、代理、告警等多个组件。MiBeeSteward 做的不是另一个 Zabbix——它是 KISS 原则的设备管理与轻量监控,适合中小规模部署。
领域三:网络发现与拓扑
| 特性 | MiBeeSteward Scanner v2 | Nmap | OpenNMS | Netdisco |
|---|---|---|---|---|
| 定位 | 发现 + 识别 + 管理 | 纯扫描器 | 全栈网管 | 网络发现 |
| 插件架构 | ✅ 5 层插件 | ❌ NSE 脚本 | ⚠️ 有限 | ❌ |
| 服务推理 | ✅ 自动分类(摄像头/Web/DB/SSH…) | ❌ 端口号推测 | ❌ 靠配置 | ✅ MAC/OUI |
| DL 级联发现 | ✅ 自动级联深度采集 | ❌ | ❌ | ❌ |
| eBPF 被动 | ✅ 可选 | ❌ | ❌ | ❌ |
| 持久化 | ✅ SQLite 自动 | ❌ 需脚本 | ✅ PostgreSQL | ✅ PostgreSQL |
| 部署复杂度 | 低 | 低 | 高 | 中 |
Nmap 是网络发现的王者,但它的输出是一条线(开放端口),你需要自己去理解这条线的业务含义。MiBeeSteward 的 Scanner v2 试图做的是把「开放端口」翻译成「这台设备是摄像头,型号是 Hikvision DS-2CD2xx,跑了 RTSP 和 ONVIF」。
领域四:Prometheus 生态融合
| 特性 | MiBeeSteward | Prometheus + node_exporter | Grafana |
|---|---|---|---|
| 角色 | 管理与监控一体化 | 指标采集 | 可视化 |
| 设备管理 | ✅ 原生 | ❌ 需要额外系统 | ❌ |
| 自动发现 | ✅ /sd HTTP SD | ⚠️ file_sd / consul_sd | ❌ |
| 指标暴露 | ✅ 原生 /metrics | ✅ node_exporter | ❌ |
| 全链路 | ✅ 单二进制 | 需要 Prometheus + node_exporter + Grafana | 搭配 Prometheus |
| 初次搭建时间 | ✅ 5 分钟 | 30 分钟+ | 15 分钟+ |
MiBeeSteward 填补的是 Prometheus 生态里「设备管理和自动发现」的空白。Prometheus 本身只做指标采集,node_exporter 只暴露主机指标,Cortex/Thanos 做长期存储——但谁告诉你有哪些设备要监控?这是 MiBeeSteward 的位置。
领域五:NVR / 摄像头平台
| 特性 | MiBeeSteward | Frigate | Shinobi | ZoneMinder | Scrypted |
|---|---|---|---|---|---|
| 定位 | 设备管理(含摄像头发现) | AI NVR | 传统 NVR | 传统 NVR | HomeKit 桥接 |
| 录像 | ❌ | ✅ MP4 分段 | ✅ | ✅ | ✅ |
| AI 识别 | ❌ | ✅ 强大(Coral TPU) | ⚠️ 插件 | ⚠️ 插件 | ✅ |
| 摄像头发现 | ✅ RTSP+ONVIF 自动识别 | ❌ 手工配置 | ❌ 手工配置 | ❌ 手工配置 | ❌ 手工配置 |
| HomeKit | ❌ | ❌ | ❌ | ❌ | ✅ 原生 |
| 资源占用 | < 100MB | ~500MB+ (含 AI) | 中 | 中 | 中 |
MiBeeSteward 不是 NVR,它不录像。但我选择了内置 RTSP/ONVIF 分类器,因为在网络扫描时能够自动识别摄像头设备和品牌——这对运维人员了解「我的网络里有哪些摄像头」非常有用。如果需要录像,搭配同一个工作室的 MiBeeNvr 即可。
综合对比总结
flowchart TD
MS["MiBeeSteward"] --> CORE["单二进制覆盖<br/>4 个领域"]
CORE --> DM["设备管理"]
CORE --> NM["网络监控"]
CORE --> ND["网络发现"]
classDef ms fill:#FFF3E0,stroke:#E65100,color:#BF360C
classDef core fill:#E8F5E9,stroke:#2E7D32,color:#1B5E20
classDef dom fill:#E3F2FD,stroke:#1565C0,color:#1565C0
class MS ms
class CORE core
class DM,NM,ND domMiBeeSteward 横跨三个传统领域。与传统专精工具的对比如下:
flowchart TD
DM["设备管理"] -->|"vs NetBox"| A["资产管理<br/>不关心在线"]
NM["网络监控"] -->|"vs Zabbix"| B["重型平台<br/>部署复杂"]
ND["网络发现"] -->|"vs Nmap"| C["端口推测<br/>无业务语义"]
classDef left fill:#FFF3E0,stroke:#E65100,color:#BF360C
classDef right fill:#E3F2FD,stroke:#1565C0,color:#1565C0
class DM,NM,ND left
class A,B,C rightMiBeeSteward 的差异化优势
看了上面的对比,你会发现 MiBeeSteward 在任何一个细分领域都不是「功能最全」的——Zabbix 告警更完善,NetBox 资产管理更规范,Nmap 扫描更全面。但 MiBeeSteward 的优点在于定位:
1. 设备管理的一体化入口
大部分团队的设备管理流程是割裂的:
- 设备上架 → 在 NetBox 录入(或者 Excel 写一笔)
- 设备监控 → 在 Zabbix 添加主机
- 网络扫描 → 跑 Nmap 存 XML
- 指标采集 → 搭 Prometheus + 配 node_exporter
MiBeeSteward 把这个流程压成了一个命令:配置好网段,点一下扫描,设备自动入库、自动分类、自动生成心跳配置、自动暴露到 Prometheus。
2. 单二进制、零依赖
这是纯 Go + modernc.org/sqlite(CGO-free)的天然优势。
对比 Zabbix(至少需要 Server + DB + Web + Agent 四个组件)或者 Prometheus 栈(Prometheus + node_exporter + Grafana + 注册中心),MiBeeSteward 的场景是小团队、多台分散设备、不想维护基础设施。
| |
不需要装数据库、不需要配 Nginx、不需要装 Java/Python/Node 运行时。ARM64 优先设计,在树莓派或小主机上跑毫无压力。
3. Scanner v2 的独特设计
用插件架构做网络发现服务化的思路在开源项目中比较少见。5 层解耦使得新增一个协议只需要写两个小文件(Classifier + Handler),其余四层完全不用碰。
级联深度采集更是独有——发现 HTTP 后自动去扫 /metrics,发现 Prometheus 端点后自动检测 node_exporter,自动解析 CPU/内存/内核版本。这种「扫一个发现一串」的能力,目前没有找到同类实现。
4. eBPF 的创新尝试
虽然 eBPF 被动观测是实验性功能,但这个思路是有价值的——传统的网络扫描本质上是主动发送探测包,对于一些敏感环境(工业控制、医疗设备),主动探测可能被防火墙拦截或者被设备认为是攻击行为。eBPF 被动嗅探提供了一个「只看不说」的观测视角。
适用场景与局限性
最适合的场景
- 工作室 / 实验室设备管理 — 20-100 台设备,需要知道谁活着、跑了什么服务
- 边缘机房 — 没有专职运维,需要极简部署方案
- IoT/嵌入式设备集群 — ARM64 小主机集群,低资源占用是刚需
- Prometheus 生态补充 — 已经有 Prometheus 但没有设备管理与自动发现
- 摄像头网络摸底 — 快速了解网络中有哪些摄像头、什么品牌、什么协议
不适合的场景
- 大型企业监控(>500 设备)— 这时候 Zabbix/Checkmk/OpenNMS 更合适
- 需要完善告警 — MiBeeSteward 不做告警,需搭配 Alertmanager
- 需要长期历史数据 — 历史数据依赖 Prometheus + Cortex/Thanos
- 纯 NVR 需求 — 请用 Frigate 或 MiBeeNvr
- 网络性能监控(流量分析、延迟抖动)— 这不是 MiBeeSteward 的目标
未来规划
目前 MiBeeSteward 处于早期阶段(刚开源),后续规划围绕几个方向:
- Scanner v2 更多分类器 — Modbus(工业)、MQTT 代理、数据库直连检测
- 告警规则引擎 — 在设备侧做简单的阈值判断
- 批量固件/配置管理 — 通过 SSH/SNMP 下发配置
- 更多的 eBPF 探针 — 观测网络延迟、丢包、TCP 重传等
写在最后
MiBeeSteward 不是一个想要「替代」Zabbix 或 NetBox 的项目——它对我的价值在于填补了它们之间的缝隙。
做运维的都知道,小团队的痛不是某个功能不够强,而是工具太多、配置太散、部署太重。MiBeeSteward 的选择是:反其道而行,把「必须的东西」塞进一个二进制,下载就能跑,跑了就能用。
项目开源在 https://github.com/Mi-Bee-Studio/MiBeeSteward ,采用 PolyForm Noncommercial 许可证(非商业免费使用)。如果它解决了你的某个问题,给个 Star 就是最大的鼓励。
如果你有想法或者建议,欢迎提 Issue 讨论。