社区VM对指标流聚合能力分析与问题
VictoriaMetrics开源项目的原生能力
VictoriaMetrics项目中的流聚合能力是从1.86版本开始整合到vmagent的,具体可参考:
https://github.com/VictoriaMetrics/VictoriaMetrics/issues/3460
从源码分析来看,流集合能力如图:

核心计算的代码在pushSample函数中有描述:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| func (as *totalAggrState) pushSample(inputKey, outputKey string, value float64) {
currentTime := fasttime.UnixTimestamp()
deleteDeadline := currentTime + as.intervalSecs + (as.intervalSecs >> 1)
again:
v, ok := as.m.Load(outputKey)
if !ok {
v = &totalStateValue{
lastValues: make(map[string]*lastValueState),
}
vNew, loaded := as.m.LoadOrStore(outputKey, v)
if loaded {
v = vNew
}
}
sv := v.(*totalStateValue)
sv.mu.Lock()
deleted := sv.deleted
if !deleted {
lv, ok := sv.lastValues[inputKey]
if !ok {
lv = &lastValueState{}
sv.lastValues[inputKey] = lv
}
d := value
if ok && lv.value <= value {
d = value - lv.value
}
if ok || currentTime > as.ignoreInputDeadline {
sv.total += d
}
lv.value = value
lv.deleteDeadline = deleteDeadline
sv.deleteDeadline = deleteDeadline
}
sv.mu.Unlock()
if deleted {
goto again
}
}
|
流聚合能力的一般运用分析
首先先看看流聚合后的时序图:
这时候,我们看看时序数据的理论形态
基于理论形态的理想流聚合形态
在实际状态下的流聚合形态
原生流聚合能力的日常问题
采集断点问题
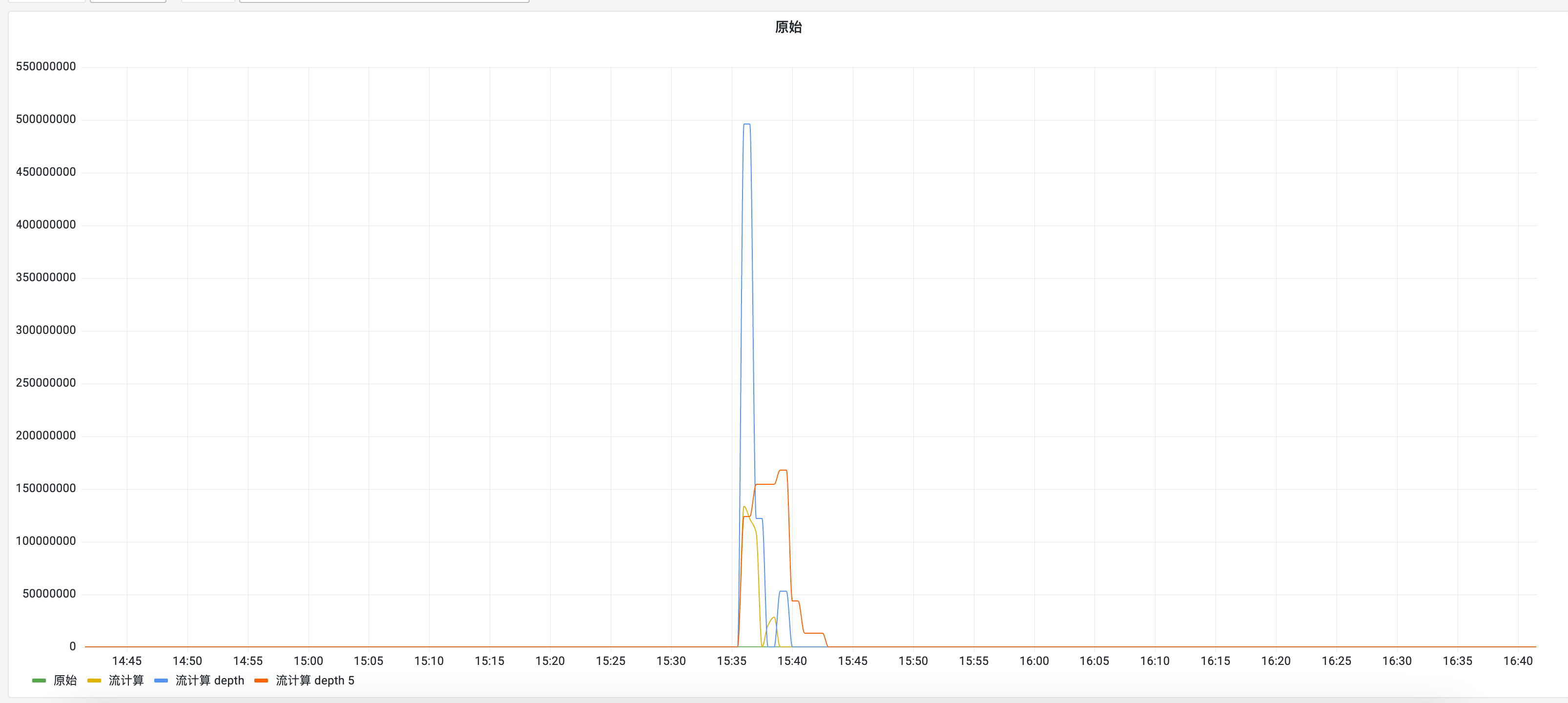
在现实世界是更残酷的,某个时间断点是无可避免,原因很多,有网络上的、有被采集服务的性能问题等。
高精度的流聚合断点问题在大数计算情况下,影响是很极端的:
巨量数据的算力架构
流聚合没有历史数据细节的状态保存,因此性能极优,但是再优性能的服务也存在单点的极限值。在处理单点无法处理的数据量级情况下,分布式算力结构就会存在一系列问题要解决:
在实际测试过程中,启动vmagent分片加副本采集能力结合实时流聚合,资源使用大幅增加,在量级极大的情况下频繁出现采集连续断点的问题,恶化了断点导致的计算结果差异问题。
架构图参考:
需计算的Sample数据分别给哪个算力点计算?
多个算力点计算后的同维度指标集因同维度同时间窗口但不同结果值导致后到值丢弃的问题如何解决?(触发乱序指标处理逻辑)
分布式计算的资源均衡问题?
插入任务id解决计算点同维度分辨问题后再次引入新维度如何解决?
分布式流聚合的网关设计与实现
上述章节分析了目前业界方案结合实际场景遇到的问题分析后,这一节会有针对性的对问题一一解决。
通过源码分析有两个关键部分:
1
2
3
| //窗口的范围是间隔设置加上间隔向右位移1位
currentTime := fasttime.UnixTimestamp()
deleteDeadline := currentTime + as.intervalSecs + (as.intervalSecs >> 1)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| // 从缓存读取需聚合的指标
v, ok := as.m.Load(outputKey)
if !ok {
v = &totalStateValue{
lastValues: make(map[string]*lastValueState),
}
vNew, loaded := as.m.LoadOrStore(outputKey, v)
if loaded {
v = vNew
}
}
sv := v.(*totalStateValue)
sv.mu.Lock()
deleted := sv.deleted
if !deleted {
// 从聚合后指标的缓存里面查找流入的时间线的记录值
lv, ok := sv.lastValues[inputKey]
if !ok {
// 如果没有记录值,则取原始值作为记录值
lv = &lastValueState{}
sv.lastValues[inputKey] = lv
}
d := value
if ok && lv.value <= value {
// 如果有记录值,则取新值与记录值的差值作为聚合后指标的追加值
d = value - lv.value
}
if ok || currentTime > as.ignoreInputDeadline {
sv.total += d
}
lv.value = value
lv.deleteDeadline = deleteDeadline
sv.deleteDeadline = deleteDeadline
}
|
从源码解读,流聚合逻辑只对时间窗口做了简易的周期判断,在流入指标因各种原因导致延迟抵达的问题导致计算值被放大没有太多逻辑处理。
这时候,我们需要一个前置模块来解决一些问题,也因vmgateway是企业组件,所以我们开发了一个属于自己的分布式流聚合的网关vm-receive-route。
分布式流聚合网关处理的问题
异步
大部分的
remote write项目
都是同步转发的。比如
prometheus-kafka-adapter
就是等kafka完成数据生产逻辑后才完成整个写流程,从而处理下一批remote write的数据。
但是流计算对数据处理是有窗口限制的,如果用同步逻辑阻塞在这里,就会影响性能,导致后续的时间sample会延迟,延迟错过了流计算的时间窗口的话,就会出现计算偏差。所以这里适合异步转发。
时间窗口的过滤
因流聚合逻辑已经对时间线的差值做了前后大小的判断,这里就不需要引进
out-of-order算法
网关这里只需要配合流聚合逻辑的时间窗口做sample过滤丢弃则可。
主要解决因网络导致Prometheus重试发送大量积压旧sample影响实时值的计算结果,也解决了Prometheus重试大量积压sample引发的资源性能问题。
维度控制
由于流聚合组件会给每条聚合后时间线插入一个节点ID来区分label。但是随着节点的横向扩容,这个label的维度也会随之增加。这里需要有一种控制维度的能力,并且能同时把时间线按维度ID来给不同的节点处理。后面我们设计了一个双重hashmod调度分配任务算法来解决这类问题。
把标记taskid的能力前置到网关,这样就可以无视整个结构的横向扩容的节点数对任务ID维度的影响
双重hashmod调度分配任务
略
后端异常服务转移
略
程序流程逻辑图
线上环境架构图
Record Rule维度任务生成器
流聚合计算是一种实时处理和分析大量数据流的技术。其主要目的是从高速、连续不断的数据流中提取有价值的信息,例如:计算平均值、求和、最大值、最小值等。流聚合计算通常会在内存中进行,以保持较低的延迟和高吞吐量。
流聚合计算的实现通常包含以下几个关键部分:
- 数据源和数据接收器:设定和监控数据流,如:日志、网络数据包、传感器数据等,将数据流分为多个小批次。
- 窗口操作:数据流会被分成一系列固定或滑动窗口。每个窗口内的数据会进行预先定义的聚合操作。
- 聚合函数:对窗口内的数据进行各种操作,例如:计数、求和、均值、最大/最小值等。
- 输出:将聚合结果输出或存储,以备进一步处理或实时数据可视化。
在指标流聚合中,该能力是对单一指标做高效的降维计算,但是在现实中要描述复杂场景是需要对多指标来结合函数计算的。
流聚合可以高效解决以下聚合过滤req_path的字段
1
2
3
4
5
6
7
| a_http_req_total{zone="bj",src_svr="192.168.1.2",src_port="30021",dis_svr="192.168.2.3",dis_port="8080",code="202",req_path="/xxxx/yyyy?abc=exg"}
a_http_req_total{zone="bj",src_svr="192.168.1.2",src_port="30023",dis_svr="192.168.2.3",dis_port="8080",code="202",req_path="/xxxx/yyyy?abc=sdf"}
a_http_req_total{zone="bj",src_svr="192.168.1.2",src_port="10021",dis_svr="192.168.2.3",dis_port="8080",code="202",req_path="/xxxx/yyyy?abc=fasdfa"}
a_http_req_total{zone="bj",src_svr="192.168.1.2",src_port="20210",dis_svr="192.168.2.3",dis_port="8080",code="202",req_path="/xxxx/yyyy?abc=asdfe"}
a_http_req_total{zone="bj",src_svr="192.168.1.2",src_port="20211",dis_svr="192.168.2.3",dis_port="8080",code="202",req_path="/xxxx/yyyy?abc=sfadsf"}
a_http_req_total{zone="bj",src_svr="192.168.1.2",src_port="21210",dis_svr="192.168.2.3",dis_port="8080",code="500",req_path="/xxxx/yyyy?abc=caresaf"}
a_http_req_total{zone="bj",src_svr="192.168.1.2",src_port="30121",dis_svr="192.168.2.3",dis_port="8080",code="400",req_path="/xxxx/yyyy?abc=werads"}
|
1
2
3
| agg_a_http_req_total{zone="bj",src_svr="192.168.1.2",dis_svr="192.168.2.3",dis_port="8080",code="202"}
agg_a_http_req_total{zone="bj",src_svr="192.168.1.2",dis_svr="192.168.2.3",dis_port="8080",code="500"}
agg_a_http_req_total{zone="bj",src_svr="192.168.1.2",dis_svr="192.168.2.3",dis_port="8080",code="400"}
|
但是我们最终要做展示的是某个目标地址的成功率:
1
2
3
4
5
6
7
8
9
| sum by (dis_svr)
(
rate(a_http_req_total{code=~"2.*"}[5m])
)
/
sum by (dis_svr)
(
rate(a_http_req_total{}[5m])
)
|
我们可以利用Prometheus的Record Rule来直接算聚合场景指标。
1
2
3
4
5
6
7
8
| groups:
- name: a_http_req_total:sum:rate:5m
rules:
- expr: sum by (src_svr,dis_svr,code)
(
rate(a_http_req_total{}[5m])
)
record: a_http_req_total:sum:rate:5m
|
但是Record Rule会把指标a_http_req_total的所有维度数据加载到内存,如果维度达到临界值就会触发内存OOM。即使没有达到临界值,该计算量也会随着维度增加以致计算结果点被延迟。
在实际生产环境中,istio_request_total的qps数据会延迟20分钟之久。
在结合流聚合计算把维度降低,使时间线从千万级别降低到万级别,也只是从20分钟的延迟降低到1-2分钟。
流聚合后的Record Rule的配置:
1
2
3
4
5
6
7
8
| groups:
- name: agg_a_http_req_total:sum:rate:5m
rules:
- expr: sum by (src_svr,dis_svr,code)
(
rate(agg_a_http_req_total{}[5m])
)
record: agg_a_http_req_total:sum:rate:5m
|
通过分析Rule模块的源码,我们可以做更细化的配置能力:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| groups:
- name: agg_a_http_req_total:sum:rate:5m-2xx
rules:
- expr: sum by (src_svr,dis_svr,code)
(
rate(agg_a_http_req_total{code=~"2.**"}[5m])
)
record: agg_a_http_req_total:sum:rate:5m
- name: agg_a_http_req_total:sum:rate:5m-4xx
rules:
- expr: sum by (src_svr,dis_svr,code)
(
rate(agg_a_http_req_total{code=~"4.**"}[5m])
)
record: agg_a_http_req_total:sum:rate:5m
- name: agg_a_http_req_total:sum:rate:5m-5xx
rules:
- expr: sum by (src_svr,dis_svr,code)
(
rate(agg_a_http_req_total{code=~"5.**"}[5m])
)
record: agg_a_http_req_total:sum:rate:5m
|
这样我们就可以通过对某个维度标签拆分的查询,以达到生成同样的新指标并发处理能力。
问题是,生产的维度标签大多数是动态变化的,我们怎么去动态生成这种按维度标签拆分的查询来实现并发Record Rule呢?我们需要一个对标签元数据的管理系统来对标签维度元数据进行跟踪和管理。
这时候我们实现了一个小型的元数据watch模块和rule build模块来解决该问题。
该组件ruler-handle-process的配置是这样子的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| recode_rules:
- interval: 5m
recode_to: istio_requests_total:sum:rate:5m
metric_name: istio_requests_total
aggr_type: sum
vector_type: rate
vector_range: 5m
group_by_and_filter:
- source_workload
- destination_workload
- cluster
- namespace
group_by:
- response_code
- namespace
- source_workload_namespace
- destination_workload_namespace
- destination_service_name
- cluster
- reporter
filter_by:
cluster: "k8s-hw-bj-xxxxxx"
with_out:
source_workload: "ingressgateway-workflows"
|
ruler-handle-process就会watch指标名"istio_requests_total"下的response_code、namespace、source_workload_namespace、destination_workload_namespace、destination_service_name、cluster、reporter的维度组合来生成一堆Record Rule规则。
结合Rule组件来实现并发计算,我们就可以把计算延迟缩短到秒级完成。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| groups:
- name: istio_requests_total:sum:rate:5m-7218756fe8a0bc327e818812cefb02f7
rules:
- expr: sum by (request_protocol, grpc_response_status, response_code, svr_response_code,
namespace, source_workload_namespace, destination_workload_namespace, destination_service_name,
cluster, reporter, source_workload, destination_workload, cluster, namespace)
(rate(istio_requests_total{cluster="k8s-hw-bj-1-prod",destination_workload="skyaxe-778-flink",namespace="istio-ingress",source_workload="ingressgateway-streaming"}[5m]))
record: istio_requests_total:sum:rate:5m
- name: istio_requests_total:sum:rate:5m-8e30244048f8d5519a6332f309578ed4
rules:
- expr: sum by (request_protocol, grpc_response_status, response_code, svr_response_code,
namespace, source_workload_namespace, destination_workload_namespace, destination_service_name,
cluster, reporter, source_workload, destination_workload, cluster, namespace)
(rate(istio_requests_total{cluster="k8s-hw-bj-1-prod",destination_workload="t-bean-portal",namespace="coin",source_workload="unknown"}[5m]))
record: istio_requests_total:sum:rate:5m
- name: istio_requests_total:sum:rate:5m-ea2d81ce1c35a7ba5a72b9e23fe7faf6
rules:
- expr: sum by (request_protocol, grpc_response_status, response_code, svr_response_code,
namespace, source_workload_namespace, destination_workload_namespace, destination_service_name,
cluster, reporter, source_workload, destination_workload, cluster, namespace)
(rate(istio_requests_total{cluster="k8s-hw-bj-1-prod",destination_workload="wefly-ad-report",namespace="wf",source_workload="wefly-app-packages"}[5m]))
record: istio_requests_total:sum:rate:5m
|
指标流聚合在监控平台的架构组合
在我们利用社区开源程序和我们的自研组件,在不同采集量场景下可以做不同的组合来解决不同量级的高维度数据。
万级别单一指标的流聚合
万级别多指标的计算聚合
百万级别以上的单一指标流聚合
百万级别以上的指标对场景的计算聚合
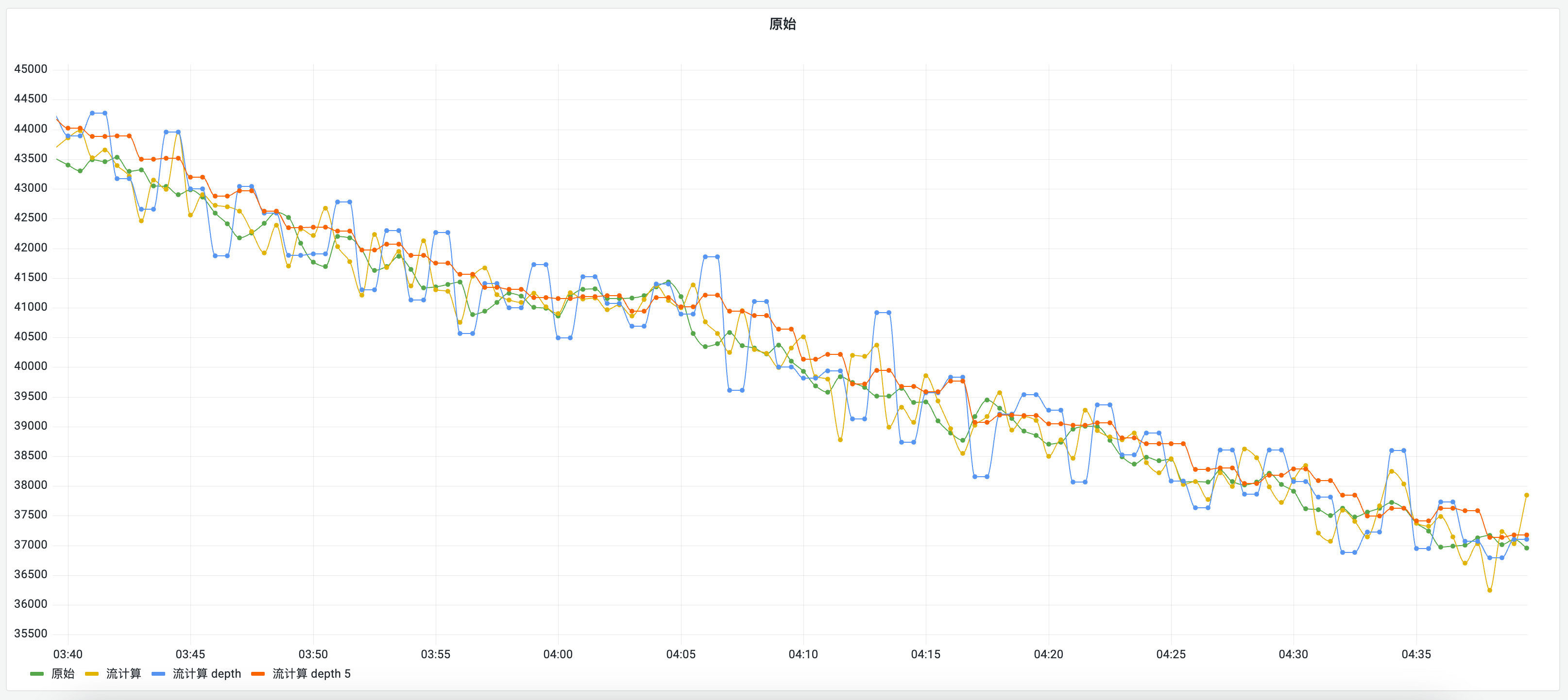



 高精度的流聚合断点问题在大数计算情况下,影响是很极端的:
高精度的流聚合断点问题在大数计算情况下,影响是很极端的:
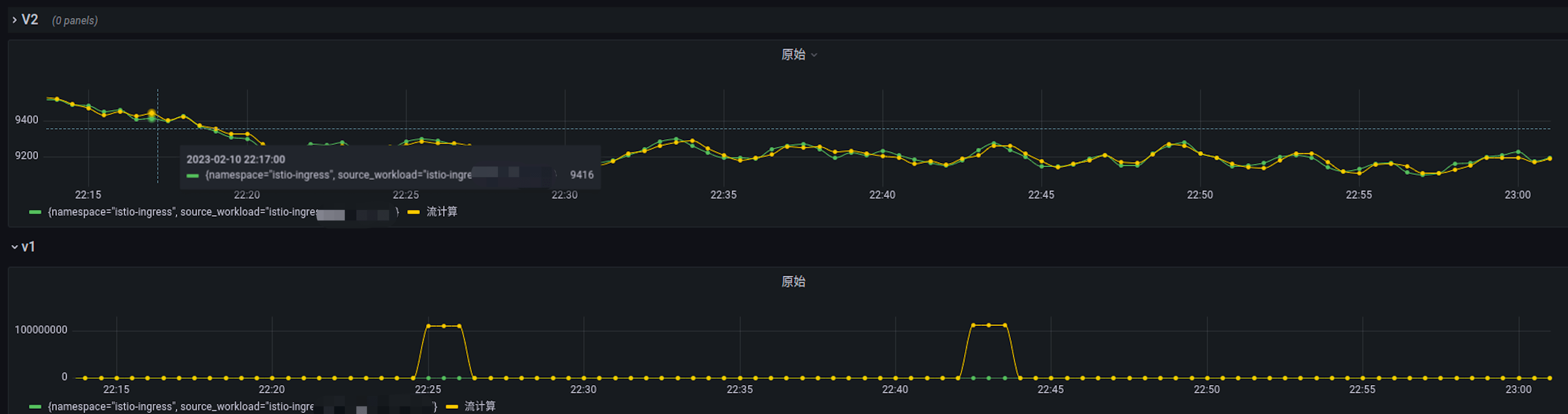 架构图参考:
架构图参考:










